The Law of Requisite Variety tells us that, the more complex your control of an environment, the more limited the space of outcomes. This is usually framed in a positive manner - you can pin down the response by adding controls - but in a pull media environment, like most social media, that's not a plus. Add complexity to what you say, and you diminish your likely audience.
Google+ has resurfaced the discussion on the purpose of the 140 character limit. Experience tells us that Twitter is a horrible medium for debate, but a fantastic medium for sparking debate.
Keeping messages below 140 characters keeps conversation starters short and open, and that is very fruitful as conversation seed material. It does however also mean that you can only seed conversations. There is limited scope for definite statements that lock a debate down, once a consensus begins to emerge. For that you need to go off Twitter. G+ is designed differently. The entire conversation can stay in one medium. I'm guessing conversations will lock down much better because of it.
Maybe the lack of limits won't matter for G+, because we're used to the short stuff by now, and stick to it for transmittability. But that advantage of course will only last if G+ is a failure, otherwise the new medium will shape the perception of what's possible and appropriate.
So Wolfram Alpha - much talked about Google killer - is out. It's not really a Google killer - it's more like an oversexed version of the Google Calculator - good to deal with a curated set of questions.
The cooked examples on the site often look great of course, there's stuff you would expect from Mathematica - maths and some physics, but my first hour or two with the service yielded very few answers corresponding to the tasks I set my self.
I figured that one of the strengths in the system was that it has data not pages, so I started asking for population growth by country - did not work. Looking up GDP Denmark historical works but presents meaningless statistics - like a bad college student with a calculator, averaging stuff that should not be averaged. A GDP time series is a growth curve. Mean is meaningless.
Google needs an extra click to get there - but the end result is better.
I tried life expectancy, again I could only compare a few countries - and again, statistics I didn't ask for dominate.
Let's do a head to head, by doing some stuff Google Calculator was built for - unit conversion. 4 feet in meters helpfully over shares and gives me the answer in "rack units" as well. Change the scale to 400 feet and you get the answer in multiples of Noah's Ark (!) + a small compendium of facts from your physics compendium...
OK - enough with the time series and calculator stuff, let's try for just one number lookup: Rain in Sahara. Sadly Wolfram has made a decision: Rain and Sahara are both movie titles, so this must be about movies. Let's compare with Google. This is one of those cases where people would look at the Google answer and conclude we need a real database. The Google page gives a relief organisation that uses "rain in sahara" poetically, to mean relief - and a Swiss rockband - but as we saw Wolfram sadly concluded that Rain + Sahara are movies, so no database help there.
I try to correct my search strategy to how much rain in sahara which fails hilariously by informing me that no, the movie "Rain" is not part of the movie Sahara. Same approach on Google works well.
I begin to see the problem. Wolfram Alpha seems locked in a genius trap, supposing that we are looking for The Answer and that there is one, and that the problem at hand is to deliver The Answer and nothing else. That model of knowledge is just wrong, as the Sahara case demonstrates.
The over sharing (length in Noah's Ark units) when The Answer is at hand doesn't help either, even if it is good nerdy entertainment.
Final task: major cities in Denmark. The answer: We don't know The Answer for that - we have "some answers" but not The Answer, so we're not going to tell you anything at all.
Very few questions are really formulas to compute an answer. And that's what Wolfram Alpha is: A calculator of Answers.
Kunstig Intelligens er som regel noget med elegante søgealgoritmer. Man har en masse data, og vil gerne vide noget om dem, og så bruger man en af en række af elegante søgealgoritmer; der er forskellige snit - brute force, optimale gæt, tilfældige gæt. Inde i kernen af sådan en algoritme ligger der en test, der viser om man har fundet det man ledte efter.
Det er jo enkelt nok at forstå, når man ikke bare kigger på det magiske resultat. Mere punket bliver det, når testen der er kernen i algoritmen, udføres af en laboratorierobot. Altså af en rigtig fysiske maskine, der arbejder med rigtig fysiske biologiske systemer i laboratoriet.
Sådanne maskiner findes faktisk, ihvertfald en af dem. Og den har lige haft et gennembrud og isoleret et sæt gener, der kodede for et enzym, man ikke kendte den genetiske kilde til.
Wiredartiklen har mange flere detaljer, hvad der gør det ekstra trist at vide at Wired Online lige er blevet skåret drastisk ned af en sparekniv.
Der kom endelig en ny Mac Mini, men den er alt for dyr.
Til gengæld er Wireds lange historie om den spæde fødsel af enkelt-neuron hjernemanipulation tvangslæsning.
Ad to omgange (1 og 2) insisterer Bruce Sterling på at verden ikke gør sådan som planen/ideologien/arkitekturen synes den skal og det har han helt sikkert ret i.
Og de her links synes jeg så iøvrigt du skulle prøve at læse med arc90s lækre Readability bookmarklet.
I can't think of a better post to have ID 4000 than a link to this remarkable test of genetic programming. Can you paint the Mona Lisa with just 50 polygons?
(as some people in the comments point out: "It's not really the genetic algorithm, but a stochastic hill climber")
Actual 4K posts won't happen in a good while, I'm at 3700 or something.
The slow ongoing dissolution of the soul - a topic near and dear to classy.dk as part of our ongoing Hypercomplex Society coverage - was the subject of this Tom Wolfe essay some 11 years ago. The title of the essay, repurposed by The Guardian to describe more posthuman thinking by Francis Fukuyama six years ago.
There are plenty of non-nightmare futures where the dissolve remains the case.
- You might remember George Dyson's powerful writing about a visit to Google and the sense that search would ultimately make something we would call intelligent? He revisits the theme in fictional form in the most recent edition of Edge.
- Nice looking video experiment
- Gnip looks like a very promising bit of hosted infrastructure - an infrastructure for following all of Digg/Twitter/You name it without feeling like a leech. It's what gnip is there for!
- Finally got some robust OSC data off my wiimotes, using Ubuntu in a VMWare Player on my Windows laptop and this hack. Writeup (and a tar.gz file) forthcoming on the hacks blog. Julian, the originator of the hack, is also the source for the amazing world-in-a-cube game Levelhead, made using the ARToolkit.
- Via Julian's blog I am reminded of this totally awesome video of 1000 runs through a racing game, artfully superimposed into one operatic 1K-car race performance.
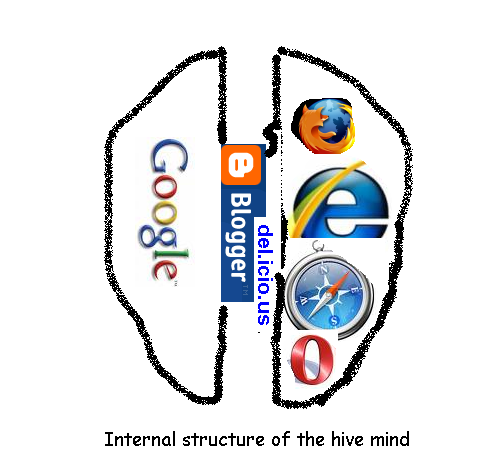
With upfront apologies for applying neuroanatomical fairytales on left vs. right brain: Let's suppose there's a truth in it about different brain capabilities: The above is a model of hive mind capabilities: Browsers observe the web, aggregators feed the observations, suitably noise filtered, to a learning-and-compression facility. As is evident from the above, we are undersupplied with learning-and-compression* engines. I could have named the other search engines like I name the browsers, but they just do the same thing, whereas you and I don't do the same thing at all when we scan the web. What we need is an explosion in specialised search and some "smart" way of using all that search at once.
*Indexing is compression and compression is knowledge.
Super spændende serie af blogposts, hvis man er interesseret i emnet forstås, starter her, svar her, men gå bare direkte til konklusionen her om hvorvidt Lakoffs "Metaphors we live by" er en samling af "Just So" historier eller har en fornuftig kognitiv basis. Jeg er ved at læse den for tiden og den virker umiddelbart suspekt - som en tryllekunst, velgennemført men dog et trick. At der nede i bunden et eller andet sted er noget om snakken i nogen af tilfældene er ikke rigtig nok til at redde bogen hjem, synes jeg - det er jo ikke særlig overraskende at vi fylder nye ord ind i skemaer vi kender godt.
Som rapporteret over det hele har en gruppe IBM forskere simuleret et nervesystem på størrelse med en mus i nogenlunde naturlig hastighed. I forbifarten noterer vi os at det har stået på en af forskernes blog i to måneder.
I believe that such cortical simulators are the linear accelerators of neuroscience. We are already able to study extremely large-scale cortical dynamics.- jeg var egentlig lidt overrasket over at det allerede var nu man havde skalaen. Lidt sammenligningsgrundlag: Musehjerner har ca 8 mia neuroner - menneskehjernen i størrelsesordenen 100 mia. Det vil sige vi er ikke mere end 4 fordoblinger fra at have nået det volumen. 4 fordoblinger er 6 års udvikling ifølge Moores lov. Simulationen kørte en faktor 10 for langsomt, så vi siger 3 fordoblinger mere og rammer ca 10 år. Så ét bud er at om 10 år er kunstig intelligens et rent softwareproblem. Ikke at det ikke er et meget stort og svært problem at løse altså.
(The creator of) an expert system providing bankruptcy assistance has been found guilty of illegally practicing law - because a user of the system was unable to tell that this was just an expert system. Necessary Turing angle via one of the lovely Scienceblogs.
I wonder if you can actually find turn of the (20th) century newspapers with stories about how horseless carriages were in fact now outpacing even the fastest horses? That is the only response I can think of regarding this story. Deep Blue was designed ten years ago. That's 6.6 applications of Moore's law ago, so the average PC is 80-100 times faster now. Deep Blue was a 30 CPU system running at much lover clock speeds (granted with a lot of hardwareoptimizations tailored to chess). Time to requote George Dyson:
For 30 years I have been wondering, what indication of its existence might we expect from a true AI? Certainly not any explicit revelation, which might spark a movement to pull the plug. Anomalous accumulation or creation of wealth might be a sign, or an unquenchable thirst for raw information, storage space, and processing cycles, or a concerted attempt to secure an uninterrupted, autonomous power supply. But the real sign, I suspect, would be a circle of cheerful, contented, intellectually and physically well-nourished people surrounding the AI. There wouldn't be any need for True Believers, or the downloading of human brains or anything sinister like that: just a gradual, gentle, pervasive and mutually beneficial contact between us and a growing something else.
To a mathematically trained "The structure is the end result" mind, there's something extremely interesting about Buttons, the lensless camera that downloads a flickr image taken at the exact time one clicks the camera button, instead of shooting its own. Structurally, the camera is simply a mobile phone photo downloader. But that is so far from the experience one has with the camera in hand that it is close to irrelevant to mention.
I hesitate to even say this for fear that some idiot would get the idea that I think we're entering the dream society after all (full on bullshit treatment here). The observation I'm getting at is almost the direct opposite in fact, of the dream society nonsense. What I'm saying is simply that our rational examination of the world has more modes than (language embedded) conscious thought and that these matter a great deal indeed.
You can capture some of the experential differences in thought quite easily though. A good example is the extremely simple facade and direct action of Buttons compared to the indirect and involved symbolic acts of locating a program on a cell phone, starting the program, locating the "shoot" action in the interface, triggering the "shoot" action and so on. I talked to Sascha Pohflepp about it during the NEXT exhibition. How the notion of technology you don't actively use - but that just yields its results around you - is tremendously interesting. Julian Bleecker of course loved the idea and I remember almost blogging it alongside this story on a related idea from Sony.
So, Just has a good observation about one more thing that's new in web 2.0:
Web 1.0 was 7 plus/minus 2 items, web 2.0 is 2 plus/minus 1 item.
Web applications are moving from targeting our attention capability (think altavista; think Windows) to targeting our attention sweetspot (think Google, think 37Signals).
I like it. It's like an attention economy analogue of the "It's your data" meme. It's your attention too, we shouldn't ask for too much of it.
If the dog and pony show at the Google Factory tour is anything to go by, Google already have close to perfect universal translation in the lab. The lesson learned, for artificial intelligence, is that intelligence is just data. Once you have enough to do good pattern recognition the limits for what kinds of problem require uniquely clever algorithms and what problems just require high quality pattern matching algorithms becomes very, very fuzzy.
As a future user of such a technology all I can say is that perfect translation always available online will be much like seeing the world wide web for the first time all over again. The implications of having access to this in mobile devices is even more staggering. Imagine all of a sudden being able to travel everywhere with good cell coverage and actually understanding everything in any language. The idea that I could have this ability with a cameraphone in 5-10 years, and not in some distant Star Trek universe hundreds of years away, almost brings tears to my eyes.
I'm imagining a future where the poor math skills of modern day kids, who never had to add, let alone multiply, two numbers by hand will migrate to languages as well. Obviously, if the machine can translate for you, why would you bother to learn yourself. For Danes, all 5 million of us, this is a big deal. From a situation where pessimists can see nothing but a certain death of local Danish culture, we may soon face another scenario altogether with everybody happily sticking to their own language - without that handicapping anybody in any signinficant way.
I will probably disagree with a lot of the stuff he says, but that will not detract from the Rageboy thesis on AI.
The basic problem with anti-AI philosphers is one that is actually covered from the other side in Rageboy's text via a quote from Jerry Fodor:
"There is, in short, every reason to suppose that the Computational Theory [of Mind] is part of the truth about cognition.
But it hadn't occurred to me that anyone could think that it's a very large part of the truth; still less that it's within miles of being the whole story of how the mind works. (Practitioners of artificial intelligence have sometimes said things that suggest they harbor such convictions. But, even by its own account, AI was generally supposed to be about engineering, not about science; and certainly not about philosophy.)" [p. 1; italics in original]
Brilliantly put, and exactly the reason the anti-AI position, right or wrong, while interesting, is inessential to AI. I am perfectly willing to say that AI is just engineering and that all thought-like signs emanating from the AI machine are fake, are signs only because of our interpretation, and evidence only of design, not intelligence. That is not in any way a statement about the consequences of building such a fake machine however and it says absolutely nothing about the nature of engineerable signing. If these machines can design even more sophisticated machines, can fly planes, emit texts understandable as sonnets or whatever that will have consequences regardless of our perception of their possible lack of intelligence.
That's the question I consider interesting. This simpler engineering question is still pretty out there stuff and it is very likely very difficult to design these Howard Hughes like machines (didn't the list of accomplishments I wrote above sound an awful lot like the skills of Howard Hughes?) if it is at all possible. Personally I think complexity itself will in some hard to conceive way yield at least some of these capabiliites.
Ever been to a store where they asked you to fill out a questionaire before they would show you some products? If you shop online I'm sure you have - but it would never happen in the physical world, because a sales rep understands that the concrete always wins. This basic observation seems to be what this post is about.
This is related to a previous post on how people search. You don't start by defining a strategy for your search, you just look at the first thing you can get your eyes on and test 'is this it?'. Only when that fails do you try to establish context and refine your search from there. Concrete always wins. Ideas and concepts are only there to help us when thinking concretely fails.
Incidentally, that's why Google was such a revelation, because all of a sudden concrete thinking worked for web search. Previously you just knew that you would need a strategy to succeed in a search, using plenty of expert options to rule out bad matches, or alternatively spend a lot of time poring over the first 20 results pages (which by the way is a strategy in itself - known as 'brute force')
Executive summary: The argument of David Weinberger at the start of a lengthy discussion on matter and consciousness (Joho the Blog: Why matter matters) is completely false. In fact I can't believe I didn't figure this out immediately, but sometimes you need to rephrase in your own terms to properly understand an argument.
For details, read on.
I have gone back and forth in my estimation of Searle's chinese room argument and Weinbergers concise version of it. I have now come full circle and turn back to my original position: The argument is completely false, and holds no merit.
That this is so is best understood by writing the argument down in concise notation.
The position Weinberger attacks is the position that if we can establish a 1-1 mapping (at sufficient level of detail) of a system R' to a conscious system R (in short, if R' can be said to be a simulation of R) then R' too is conscious. In mathematical notation:
If there exists a mapping c (an interpretation as simulation) of R' to R and R is conscious, then R' is conscious.
We call this the 'strong AI position'
Weinberger counters that this cannot be the case since we can construct another mapping n from R' to R that is not viewable as simulation.
Weinberger concludes that we have proved at the same time that R' is conscious and that it is non-conscious and thus that the strong AI position is meaningless. His claim is obviously false. Weinberger is confusing the contrary opposite with the logical opposite. The existence of a meaningless mapping is not the logical negative of the original claim. That would be non-existence of any simulating mapping.
Weinberger further says that consciousness of a physical object cannot be a matter of our interpretation of that object as conscious. This is obviously true, but fortunately the strong AI position is completely consistent with this position, as should be evident from the discussion above. The existence of the mapping from R' to R does not change R' in any way, and nobody is saying that it does. The difference of opinion is not on this question, but rather on whether consciousness is an observable quality of R'. The strong AI position is that it is: The simulating mapping constitutes observation of consciousness. Weinbergers position on the matter is not apparent from his argument. From his comments in the discussion and various other posts it would appear that he does admit that consciousness could be observable.
UPDATE: Weinberger's and Searle's arguments are simply, and trivially false. Read the final word (I hope) on the matter.
After a lengthy discussion on Searle's chinese room argument on David Weinbergers weblog I think I finally understand what the Searleists are getting at, even if I don't think they are making their case against strong AI.
The discussion is rather involved, but my summary of it goes like this:
Weinberger argues that the common position that we will have built intelligent, conscious machines if we can build a simulation of an actual conscious intelligence is wrong, since the simulation relies on our interpretation of it (as something symbolically equal to a conscious being) to be understood as conscious.
UPDATE: Here Weinberger confuses contrary opposite with logical opposite. Read the final word on the matter.
There's a point there, even if one might argue that interpretation is all we can do - inasmuch as language about 'stuff' is always an interpretation of said stuff.
The important thing to notice is however that Weinberger (and Searle) are actually not saying anything about the consciousness of the physical system performing the simulation, but are only dismissing the argument that it is conscious by virtue of being a simulation of a conscious system.
In short, the objection made to strong AI is what Lakatos calls 'local' - an objection to part of an argument in defense of a thesis, not 'global' - an objection to the proposed thesis itself. I think this is an important objection to the chinese room argument, and I don't recall having seen it before - but then again I am not that well read on the issue.
UPDATE: As mentioned, I think the objection is just plain wrong.
While I am not sure where this leaves us with respect to reasoning about consciousness at all, maintaining the position that consciousness can only be understood as a quality of something real (insert longish blurb on intensionality here) does provide a good explanation of some of the conundrums proposed by the mind as pattern explanation.
For example it offers an immediate answer to question of whether a copied consciousness is the same consciousness as the original. It is not - since it is not the same real object anymore.
UPDATE: The point on the reality of consciousness is well made, but not in opposition to claims made by strong AI.
The Weinberger log entry has good links to Kurzweils website on the matter (pun intended).
And I grudgingly have to admit I didn't get Weinbergers point in previous posts.
UPDATE: And then to understanding them and being fooled by them. Not my proudest moment.
On rereading the argument as presented in 'Small Pieces Loosely Joined', we find some evidence as to what Weinberger dislikes about the idea of 'patterns as consciousness' is that it does not account for our interaction with the real world: "Thinking, and thus knowledge, requires not only a brain but also a world and a body". But is anybody really saying otherwise? Surely nobody is imagining that the Kurzweil simulator does not receive input from the external world, or produce output into that world. In fact the way in which it relates input to output is exactly what we use to gauge its intelligence. It is part of the experimental setup.
And of course this input and output means the machine is not an identical performative copy of Kurzweil. Its camera eyes view the world from a different position for instance, but we should be able to reason about consciousness of this machine regardless.
In fact this observation provides us with the next attack on 'The Chinese Room'. It is the entire system claims of consciousness and/or intelligence is being made about, including the mapping to the external world. So Searle's conclusion that the Searle genie in the bottle does not know Chinese even if the Chinese room as a whole is capable of chinese translation can be true without anything having been said about strong AI.
UPDATE of UPDATE: I finally took my head out of the bucket it has been resting in for the last 4-5 days and figured out why Weinbergers argument is completely false. Read the final word on the matter.
David Weinberger is posting heavily against strong AI. I completely disagree with every point he makes, but a discussion is not forthcoming. I tried posting a couple of comments, but I either failed to make my case or just didn't put my opinion in a suitably scholarly fashion to be taken seriously. My vanity prefers the latter interpretation.
Last disagreement is on Why matter matters. Weinberger is tapping into some of the classic thought examples of philosophy and this time he offers 'formal proof' that consciousness cannot be a matter merely of patterns. But his M&M's example is no formal proof, it is a party trick.
While he successfully makes the case that pure pattern does not matter - a pattern is meaningless if the pattern is not specified with an interpretation, he does not succeed in relating that necessity to any quality of the conscious other or non-conscious other.
Weinberger is left with some kind of essentialism. There is something (and we can't really say what) that makes a person a person. It is impossible to observe (in any meaningful sense of the word) another consciousness understanding anything. When I say 'any meaningful sense' I mean 'in any way that can be defined making reference only to direct physical observation' (to the extent that this is at all possible, cf. earlier remarks).
UPDATE I:
Well, no he isn't left with essentialism, see further notes on the issue. I maintain that the Searle argument eliminates our ability to reason about the consciousness of anything. Update of Update I: It doesn't even do that it is just false. the final word on the matter.
Weinberger counters that what he is doing is taking his own consciousness as indisputable - not that of anything externally observed - but that does not get us anywhere with the chinese room, since the inability to observe consciousness remains the essential thing. The really interesting thing to do once we have the perfect brain simulator running is to refit it to run as a brain imaging device instead, and have it, not simulate a brain but rather faithfully and dynamically display the exact neuronal state of a real brain. Since Weinberger is ready to grant us the possibility of construction, he will allow that the machine will have the same state whether or not we let its own internal algorithms guide its progress or we simply set each simulated neuron through high definition recording to the state of the neuron it is an image of.
What does the chinese room argument about the brain imager/simulator then say about the synchronized real brain?
UPDATE II
Nothing at all. See further notes.
The whole thing is a throwback to one of the least readable passages from 'Small Pieces Loosely Joined'. Weinberger dismisses every counterargument to Searle's famous chinese room argument by (to my mind) blandly restating the argument. It does not improve with repetition.
UPDATE III
Actually it does improve somewhat (but not enough) with repetition. See further notes.
UPDATE of UPDATE III. It only improves if you let yourself be confused by the way it is stated. Read the final word on the matter.
Weinbergers example would have been a lot more interesting, if he had suggested an example system that really resembles a conscious system in the way we are able to observe it. Lets suppose the patterns (emanating from a conscious phenomenon or a non conscious phenomenon) that we observe is actually a couple of well-edited highly updated weblogs. What Weinberger would say is that his argument merely says that we cannot seriously consider calling the weblogs themselves conscious. So far so good. By extension of the argument Weinberger would have to maintain that we are unable from observation of the weblogs to make any judgment about the consciousness of the writers behind them. We are merely assigning meaning to essentially arbitrary configurations of pixels. This presumably would also hold if we could watch live footage of the writers, while they write. We would still be watching a simulation of the writers, so the same interpretive act that goes into the M&M's example is still in place. By what magic does that distance disappear if we were in the room with both writers present, one a cyborg, terminator style machine with human flesh and one true flesh and blood?
If it helps, we can take the example even further by imagining the cyborg being based on 'grown silicon' and having learned what is uses as a writer in a regular school alongside real human beings. Let's take it even further by assuming that the machine is a hardware based simulation at the cellular level, each cell simulated by a nano-machine. In my opinion Weinberger would have to maintain that we are still just interpreting, I don't see the room in his argument for inserting a distinction between the pure software simulation and this almost 1-1 physical simulation.
I on the other hand maintain, that the question of whether or not we can in fact construct such a machine is the real question of interest. The pure question on the possibilty of the machine and the how of building it is gigantic. The question of what role such a machine would play in society is equally baffling.
UPDATE IV
I maintain the final point of this entry, even in light of further notes. But the further notes are an important caveat wrt the understanding of constructed consciousness.
UPDATE of UPDATE IV: No change to Weinbergers example could resuce the flawed logic. Read the final word on the matter.
'Pattern does not matter' means that if you do not bind the pattern to a particular interpretation you can prove that you cannot compute from the pattern one unique reasonable interpretation ina given world.
(For pattern substitute 'language' and for world substitute 'model' - The example and the observation about the possiblity of reinterpretation is by Hilary Putnam, from 'Reason, Truth, and History' )
David Weinberger comments on The Searle vs. the world of AI controversy.
The discussion is over whether the term 'conscious' (often interpreted as 'intelligent' a word about as well defined as 'living') will ever be applicable to a machine. Searle's view is (simplified) that since we can symbolically reduce any accomplishment of the machine to a mechanical procedure, we can never call the machine intelligent.
This remains the intellectual pyrrhic victory of all time, as I have previously argued. Searly says absolutely nothing about the possible observable capabilities of machines. He merely says that regardless of machine capability he will never accept that capability as a victory for AI.
So suppose all AI researches conceded victory to Searle. They could then continue their work as if nothing had happened. Their arguments for funding would have lost no power. It is still as interesting to construct machines capable of performing the complext tasks only human beings can perform today. And as a bonus they would avoid forever a lot of interesting ethical dilemmas.
Tim Bray suggests that search engine users are about as intelligent as Homer Simpson. One word, maybe two word queries. They do not want anything else (which is why 37 signals miss the point). This would appear to also attack my xpath directory search plan but I maintain the idea with a slight iteration: People don't want to construct queries, xpath, natural language or otherwise. But they would probably appreciate a gestural search interface. That is, having said beer they might query for something more specific that is beer related - or they might follow a link and then search some more. This gestural activity suggests complex queries - and might suggest xpath.
Of course that is exactly Bray's point - and it is also the point of my software pragmatics rant. Developers spend their entire day constructing complex requests, and it hurts too damn much. Modern developemnt technique focues exactly on a conversational, gestural mode of construction that it much less painful - preferably without sacrificing precision or clarity.
Hang on, isn't the 37 signals interface gestural also? Not really. It puts up too many choices and the choices are too complicated to evaluate at a glance. That's like context unaware code completion which is just painful.
Oh, and also amen.
How many people in the world know the date The World Trade Center was attacked and collapsed? It is probably not an exaggeration to say billions of people. If we think of society as a data processing device that constitutes an enormous redundancy. This enormous redundancy applies to all human knowledge. The most prized information is not the rarest or most exotic, but rather the most common and most known information.
Within a single brain it is an open question on the other hand what the processing/memory ratio really is.
In data modeling texts (the entity-relationship kind) the ideal of information is the coherent, global data model and models emphasize qualities such as consistency and lack of redundancy. The knowledge engineering approach to the semantic web adheres to the same ideals. Much work goes into establishing semantic validation and proof systems.
I think that for practical applications, this approach is wrong. We should expect this model to break completely down and expect the web to start replicating the redundancy of human knowledge.
This, inspired by some slides on RDF and the ongoing RDF debate. I think it is completely wrong to expect the publication of RDF by everybody to matter at all. The notions built on top of RDF involving provability and consistency verification also seem to me unlikely to matter until some later time. The hope that deduction will suddenly work directly off RDF seems entirely unbelivable to me.
Indexing of RDF on the other hand could be useful on limited vocabularies published with very specific purposes. But RDF should be thought of as nothing more than a technology for distributed publication of hierarchical content. That is, RDF should only be seen as construction a tree of information in the same way XML documents do, with the only important extension being that the RDF tree of information can be distributed. The notion of proof should be condensed down to not much more than XPATH like matching of the information tree. BUT by indexing RDF, i.e. actually caching particularly valuable instances of the virtual documents RDF enables this kind of search could be made efficient.
What does data modeling is not important mean then? Only that the usefulness of the data will be built dynamically by indexers, and the indexers will just extract the information they can and handle the consistent presentation of data on their own. And also that all information on the network will be present with a great deal of redundance, cached for every purpose for which it is useful.
Google works so well because if you can think of something to say, the odds are good (well, OK at least) that somebody has thought about saying the same thing in the same way before. Add a good relevancy engine and you're rocking.
Then people start complaining. 'I wrote film, and the page I was looking for talked about movies instead. What a stupid search engine', and so the dream of natural language search is born. In reality it is not the ability to frame the questions in natural language that is so sought after, but rather the listeners ability to extract a broad meaning from the question instead of a stupid text match.
Dave Winer had an idea about search through an open directory of directories, i.e. a general search of anything remotely resembling a catogorization of knowledge.
I sort of had that idea myself a while back (before reading Dave, honest!)
Now from another perspective comes Jon Udell's idea of XPath everywhere. By cleaning up our writing and using XPath we suddenly have a powerful search functionality on our hands.
Now combine the two: Suppose we had a directory of directories/ontologies. Suppose that this directory was XPath searchable. On this data, XPath does exactly what I claim we would really want natural language search to do: Search world models in a form sufficiently close to language to be useful.
The complexity of the search and of the ontology storage must be adressed of course (clearly generating any possible ontology consistent with a given set of documents (based on word occurence) is unlikely to be feasible).
Some more related Udell thinking on this matter.
And then of course the main reason to push forward
What is really remarkable about human beings is their will and desire to circumvent even the biggest obstacles to do something - in fact anything worthwhile: Mark Pilgrim recounts a work experience:
At the same job, several of my co-workers were blind. They did the same job I did - relaying calls for the deaf - but they were blind.
Now that's an obstacle to conquer all right!
Tim Bray's challenge for a Really Useful application to donate the domain rdf.net to has led to one submission: McCullough Knowledge Explorer and the MKR language
Unfortunately the description says :
McCullough Knowledge Explorer (MKE) is an interactive tool for organizing knowledge. It helps the user to record, change and search knowledge, and provides extensive error checking to ensure the internal consistency of the knowledge.
That's doom for the product in one sentence. In closed domains maybe consistency works, but the distributed nature of the web simple has no place for notions like consistency. If it is consistent most of the time, fine - but it certainly not a design parameter of knowledge that it be consistent across meaningful volumes of information. If it were we'd be running out of words in no time.
Knowledge is always situational, and the best description of knowledge is "whatever pre-learned rules that are effective in a situation that you find yourself in". Adding more language than that puts you in the space of formal models very fast. You can start by namespacing the situational contexts and trying to make each of them consistent, but you will run into problems almost immediately if the namespacing is anything but an enumeration of situations and interpretations that have occured.
I think the theory of semiotics and signs, with the notion of infinite semiosis (i.e. reinterpretation) and no barriers at all to what constitutes signing (i.e. ideas or meanings) has it right.
EXAMPLE
As evidence of how tangled meaning is - surf the New Testament HyperConcordance. That's the full text of the New Testament, with every word indexed, and with every occurence of a word hyperlinked to the index. In short - A screenful of blue links.
Tim Bray has an interesting point in The Natural Language Query Fallacy
On computer systems with NLP: "Why would I want to speak to it in full sentences stuffed with subordinate clauses and prepositional phrases? I think I'd want to grunt things like 'Yahoo, Berlin weather' or 'break line 238' or 'spam!'."
Everyone knows of course that spoken language has its own broken grammar, and that's what you need to implement. True interface nirvana is much more akin to a gestural interface - where the computer uses one or more cameras to look at you and detect your state of mind from that (I've often dreamed of a force feedback keyboard so that Windows could drop those pesky 'Are you sure?' popups when I'm angrily beating the keyboard really hard). But that is obviously a harder task.
An interesting related fact is the rise of IDE's and visual tools and the decline of programming languages as the focus of software development attention (as discussed in the classy.dk favourite on Software Pragmatics. When proper computer languages came about in the 60s and 70s that was a revelation. These days, efficient development deemphasizes language, and in fact modern IDE's have something similar to a rudimentary gestural interface. You point and click - tab your way through lists of words to find the right one and occasionally write one or more words by hand.
In short the activity of programming is the complete gestural interaction, not the act of writing.
Revisiting the original Turing test paper - I stumbled on the Cogprints Archive og papers on Cognition. It has tons of good stuff. The original Turing paper - and also some of the good pro-AI references: Daniel Dennett's review of Searle's 'Rediscovery of Mind' and Penrose's 'Emperors New Mind' as well as papers by David Chalmers on computation and cognition.
MIT Tech Review has a nice piece on the current quality and progress in the field of natural language processing: Computers That Speak Your Language
This is as close to a live Turing test as I can think of, and basically I'm of the opinion that it doesn't really matter that much if it can be completely hidden whether or not a machine is answering you. If we are willing to internalize the interface and simply have any kind of conversation with the system, with the plan of actually reaching a goal through the use of natural language, then I will consider the test to have been passed.
I think this position is the only interesting one in AI. The argument about consciousness and 'deep understanding' is meaningless or unnecessary. Or rather: A negative answer to the question (AI is impossible) has no bearing on the evolution of technology. A positive answer on the other hand means that we will have to think about the ethics of AI. Regardless, I think the entire debate on the possibility of AI is misguided since no general argument or argument from the nature of the human brain can successfully prove the impossibility of replicating specific observed capabilities of the human mind.
Whether sophisticated machines are viewed as conscious or not has little bearing on whether or not they can be constructed, and therefore the debate about the possibility of AI is largely a debate about our perception of the machine and not of the machines perception.
Arguments from undiscovered magic abilities of the brain (e.g. Emperors New Mind) I believe are just plain wrong.
Turings original paper on artificial intelligence proposing the Turing Test that I talked about below is of course available on the net, as well it should be. I found it using the most intelligent piece of software I know, Google.
As remarked by Douglas Hofstadter in the introduction to G?del,Escher,Bach (maybe it's an addendum for the anniversary addition I have; I certainly don't recall it from first reading) it is impressive how well Turing manages to address practically all the objections to the test that have since been given, in the very first presentation of the test. Since Turing is also quite a good writer, the piece is certainly recommended.
After reading Linked one has to ask the obvious: What is the exact distribution of Google PageRanks and does Google publicise this data?
Clearly, there is renormalization wrt. search terms going on. That's why the PageRank actually works both for rare search terms and common ones. An exotic or topic specific search accesses a subnet within which PageRank in itself makes sense.
No this is not an article about a failed 2M Invest company... Actual legislation is being proposed in the US Congress to allow any copyright holder to hack the hackersas reported on K5. In short, the proposed bill provides immunity for a number of possible liabilities caused by interfering with another party's computer, if the intent was explicitly - and upfront - to foil illegal use of copyrighted material.
This is the old "If guns are outlawed only outlaws will have guns" idea. Let the good guys give the bad guys a taste of their own medicine. Only, in the virtual world, where boundaries of location (especially in a P2P world) are abstract and hard to define, it seems to me that this bill is an extension of the right to self defence and the right to protect the sanctity of the home, to actually allowing aggresive vigilante incursions on other peoples property, when the other people are accused of copyright infringement.
It goes right to the core of current intellectual property debates, and raises in a very clear way the civil right issues involved in the constant and rapidly increasing attempts at limiting right-of-use for lawfully purchased intellectual property. Whose property IS intellectual property anyway?
UPDATED 20020731
In the olden days - when intellectual property was securely tied to some kind of totem, a physical stand-in for the intellectual property, in the form of the carrier of the information, i.e. a book or an LP or similar, there was a simple way to settle the issue. Possesion of the totem constituted an interminable right of use of the intellectual property. The only intellectual property available on a per-use basis was the movies. Live performance does not count in this regard, since live performance is tied to the presence of the performer, and the consumption of live performance is not therefore a transfer of an intellectual property to the consumer, in that it is neither copyable or transferable or repeatable.
It is of course the gestural similarity with live performance that has led to the rental model for film.
As the importance of the totem began to degrade, so began the attacks on the physical interpretation of intellectual property. We have seen these attacks and reinterpretations of purchase through the introduction of casette tapes, video tape, paper copiers, copyable CD rom media, and now just the pure digital file.
At each of these turning points attempts are made to limit the right-of-use to film-like terms. Use of intellectual property is really just witnessing of a performance. So you pay per impression, and not per posession.
What is interesting of late, and in relation to the lawsuit, is both the question of whether this 'artistic' pricing model is slowly being extended from the entertainment culture to all cultural interaction. Modern software licenses are moving towards a service-model with annual subscription fees. This could be seen as a step towards pure per-use fees for all consumable culture - an idea that is at least metaphorically consistent with the notion of the information grid. Information service (including the ability to interact) is an infrastructure service of modern society, provided by information utilities, and priced in the same way as electrical power.
In practice you do not own the utility endpoints in your home - the gasmeter and the electrical power connection to the grid. And ownership of any powercarrying of powerconsuming device does not constitute ownership of the power/energy carried or consumed. In the same way the content companies would have us think of hardware. And Microsoft would like you to think of Windows as content in this respect.
Secondly, there is the important question of how this interpretation of information and culture relates copyright to civil right.
The sanctity of physical space (i.e. the right of property) is a very clear and therefore very practical measure of freedom. Actions within the physical space are automatically protected through the protection of the physical space. There are very real and important differences between what is legal in the commons and what is legel in private space. And of course the most important additional freedom is the basic premise of total behavioural and mental freedom.
The content company view of intellectual property is a challenge to this basic notion of freedom. There is a fundamental distinction between the clear cut sanctity of a certain physical space, and the blurry concept of "use".
The act of use itself can be difficult to define, as property debates over "deep-linking" make clear.
In more practical terms, any use of digital data involves numerous acts of copying of the data. Which ones are the ones that are purchased, and which ones were merely technical circumstances of use. The legislation proposed enters this debate at the extreme content-provider biased end of the scale. Ownership of anything other than the intellectual rights to content are of lesser importance than the intellectual ownership.
The difficulty of these questions compromise the notion of single use and use-based pricing. And ultimately - as evidenced by the deep-link discussions - the later behaviour of the property user is also impacted by purchase of intellectual property according to the content sellers. This is a fundamental and important difference between the electrical grid and live performance on one hand, and intellectual property on the other. Intellectual property simply is not perishable, and, as if by magic, it appears when you talk about it.
Interestingly a person with a semiotics backgorund would probably be able to make the concept of "use" seem even more dubious, since the act of comprehension of any text or other intellectual content, is in fact a long running, never ending and many faceted process. In the simplest form, you would skirt an issue such as this, and go with something simple like "hours of direct personal exposure to content via some digital device". That works for simple kinds of use, but not for complicated use. And is should be clear from endless "fair use" discussions that content owners are very aware of the presence of ideas made available in their content in later acts of expression.
A wild farfetched guess would be that as we digitize our personal space more and more, expression will be carried to a greater and greater extent over digital devices, so that the act of thought is actually external, published and visible (witness the weblog phenomenon). In such a world, the notion that reference is use becomes quite oppresive.
Ultimately the concept of free thought and free expression is challenged by these notions of property. It is basically impossible to have free thought and free expression without free reference or at least some freedom of use of intellectual materials.
Hmmm, the danish fuel-cell advocacy website brintbiler.dk thinks that the keyword 'management' was a good one to purchase on Google Adwords. I found out trying to find a link for
Either they weren't thinking when they purchased, or Google is not in proper working order, or there are hitherto unknown connections between component programmign and green high-tech energy.
Man - as previously mentioned - could degrade into biomass for information processing, if the pressure of divided attention cannot be tamed.
Listening to the radio program
This American Life | Give the People What They Want it becomes clear that we are biomass for information - and happily so - as long as were consuming and processing social information. The story is of a home for the Alzheimer plagued, where they stage fake weddings to please the diseased. The weddings are fake. Bride and groom were hired to play bride and groom. It's like Tony n'Tinas wedding without the pretense of any excitement, except that of a social situation in which you participate.
This helps the Alzheimers patients, by placing them in a social situation they can understand and consume mentally, perhaps remembering similar situations from their own life. However, since they are Alzheimer's patients, the memory of the event lasts only a few hours. The home could stage the wedding again the next day, and the attendees would attend as if yesterday had never happened.
I am reminded of a novel by the Danish novelist Svend Aage Madsen called Se Dagens Lys (literally translates to "See the Light of Day") about a man who wakes up each morning in a new world, with a new wife, and new neighbours to happily live though the social gestures of the day, and then wakes up next day with no emotional history, just more social gestures and a new but similar setting (and I am of course also reminded of "Once in a Lifetime", and "Brave New World" and "1984" and every other fictionalization of the modern emotionally disengaged life)
This whole humanistic intelligence thing is all fine and dandy - provided the new sensory experience of ever present communication impulses does not mean that we end up in an age of continuous partial attention. Neal Stephensons homepage (the link above) really does not want to be disturbed. His homepage is the longest single statement to the effect "Don't call me I'll call you" I have ever seen.
This entire thing about symbols/ideas/imagery reminds me of a talk I once heard the danish sculptor Hein Heinsen give. To put it briefly, Heinsen's approach to his work means there's a fundamental difference for him between sculpture and painting, in that the sculpture is a question of presence and being, whereas the painting is imagery and idea. As most everybody Heinsen believes there's a just too many ideas going around which of course becomes the grounding for working with sculpture. Of course the reality of it is that the sculpture as being is often a stand-in for some other 'real' being, so in fact merely the idea of being! Whereas the painting is often reduced from being an image to just being the traces of the imagining, so in fact more being. Heinsen claimed in all honesty that he was well aware of this flaw in his logic, and that his answer to the whole thing was to make very few sculptures! We should all have that luxury.
In simpler terms we can follow Stephenson and paraphrase
Donald Knuth: Email is a wonderful invention for people who want to be on top of things. I don't want to be on top of things. I want to be on the bottom of things.
Some more indications of the importance of memory bandwidth for the effective power of a computer. In this paper there's some statistics on neuron update speed, transport speed of neuronal information and brain size. It appears that the entire memory of the brain could theoretically be available to every single computation performed - at least as far as raw speed is concerned.
Also the latest Crays mentioned below localize the memory subsystems close to the processor. In the design for IBM's
Blue Gene machine the entire architecture of the machine will use merged DRAM embedding DRAM completely in the processor core (about 8 MB per processor) This may not sound like a lot, but according to the IBM scientists it suffices for the code they need to run.
On another note - as an aside to the mention of the latest Crays : This machine will pack a whopping 2^15 processor nodes - 31 times the Cray. Each node will yield 32 GFlops (3 times the Cray nodes I believe) for a total of one peta-flop i.e. 10^15 Flops. The power efficiency of the machine will be 2Megawatts per peta-flop. Orders of magnitude more efficient than the Crays mentioned below.